
This first blog post is going to present some details around the GAN and what it does, why it’s useful and why it helps to test defences. Initially, we set out on the GAN project some years ago, however owing to budget constraints, the process took much longer than expected to get to a stage 1 which we can release to the Red Team and CNO community.
With Turul GAN, there are two things at play here that I will delve into: one aspect is the code transformation, and the other aspect is why this approach was taken and also the long future vision.
Let’s Begin with the Why?
Red Teams and CNO operators must devote significant time to developing evasions both behaviorally and statically, and the EDRs evolve as time goes by addressing these evasions. Most of these methods revolve around blinding the EDR’s ML models. Techniques are discovered that allow for a wide range of methods that essentially limit the data that is being delivered to the ML model within the EDR. Whether this is encrypting and unencrypting your shellcode in memory, or doing some kind of esoteric process injection, or hiding behind an AppDomain injection, the core focus is to hide the malicious code that you are deploying away from the machine learning model that is trained on the signatures of these malicious codes.
At points throughout the lifecycle of the execution of typical Red Team strategies, the shellcode or binary that is performing your malicious actions is being exposed to the EDR ML model, and the name of the game is to not be seen.
This creates a cycle whereby you need to constantly find new ways to blind the EDR, which is resource-intensive. Our solution is a first-stage step in limiting the process of having to find these evasions and directly engage the ML model itself and offload the development of evasions to algorithms.
How Can This Be Approached?
If you think about the challenge that EDR developers face, one is that they must deal with limiting false positives, and so there are a wide range of code bases that they are trained to ignore. This evaluation will be based on a P-value threshold whereby some code at a certain threshold will be deemed benign, some code will be deemed uncertain, and some code will be deemed malicious. These kinds of values are derived from the machine learning training process where they take hundreds of thousands of malicious samples, try to learn their features, and offset this against false positives whereby non-malicious code is not inadvertently flagged.
This process obviously works both behaviorally and statically, and they have to make trade-offs in the cases where some code may be very close at once to normal code, and whereas some code maybe close to obviously malicious.
This presents challenges to the offensive security community, given that most of the tools in use are heavily signatured and the machine learning models are well-trained to evaluate unknown code that is also malicious in intent.
Engaging with ML Models Directly
To bypass EDRs effectively, we must shift our focus from simply obfuscating code to actively influencing how the ML model perceives it. If we understand the decision boundaries that an EDR model uses to classify threats, we can generate code that falls into an uncertain or benign category.
This is the space where Turul GAN seeks to work in. Instead of relying on traditional obfuscation, our system uses a generative adversarial network (GAN) to transform malicious code in a way that maintains functionality while appearing statistically benign to an ML-based EDR.
At a high level, Turul GAN operates in a two-step process:
- Code Transformation:
- The generator network modifies an input sample (e.g., implant, loader) to evade detection.
- The goal is to reshape the code’s statistical and behavioral signature while ensuring it remains operational.
- Adversarial Evaluation:
- The transformed code is tested against real-world offline EDR models.
- Feedback is used to refine the transformation process.
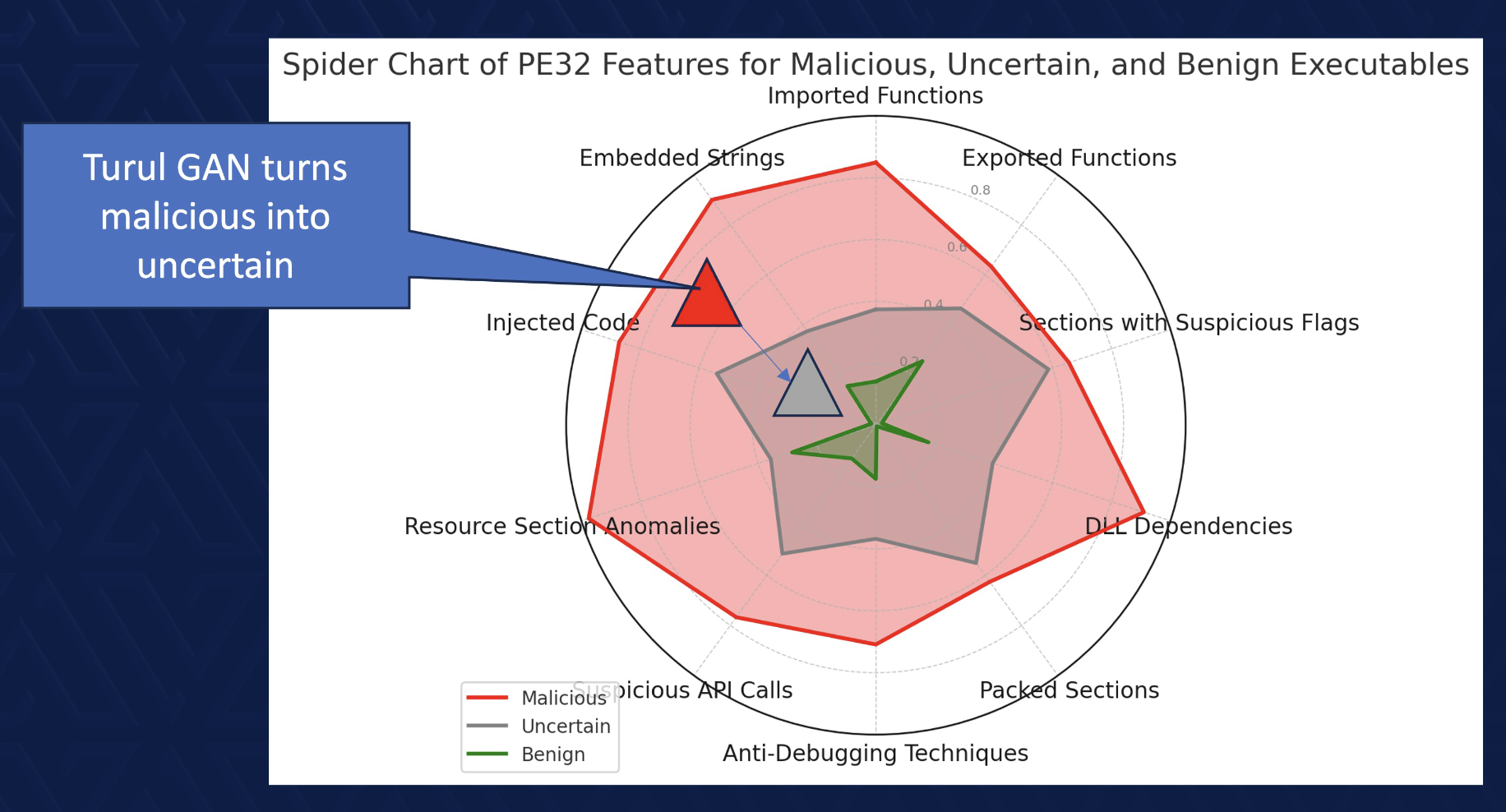
The conventional method of creating evasions requires extensive testing, reverse engineering, and manual tweaking. While effective, it’s inefficient in the long term. Machine learning, on the other hand, is trained on vast datasets and constantly adapts—so why not fight fire with fire? However, we are only at Phase 1.
Phase 1: Rule-Based GAN with Block-Based Transformation
Turul GAN currently operates on a rules-based architecture, leveraging block segmentation and semantic-preserving transformations to modify code at a structural level while ensuring functionality remains intact.
How it Works:
- Code segmentation: Malicious payloads are broken into smaller functional blocks (~70 identified segments in Turul C2).
- Static & dynamic perturbations: Each block can undergo controlled modifications (e.g., variable renaming, junk code insertion, control flow restructuring).
- Exponential polymorphism: With 270 blocks and multiple transformation states per block, the number of possible permutations reaches astronomical figures (~10⁸¹+).
This approach ensures that while the code appears different at every iteration, its execution remains unchanged, making detection significantly more challenging.
Why Phase 1? The Real-World Challenges of GANs in Code Transformation
GANs Struggle with Code Semantics
Traditional GANs excel at generating unstructured data like images or text but struggle with structured code. Code execution is binary—it either works or it doesn’t. Even a minor unintended modification can result in syntax errors, logic failures, or even entirely broken binaries.
In image generation, an ML-based GAN can generate a blurry or slightly distorted face, and it’s still a “face.” In code generation, even a misplaced bracket or minor transformation can completely break execution.
Thus using a purely ML-driven GAN from the start could generate malformed C# payloads that don’t execute correctly.
Maintaining Execution Integrity
Unlike in adversarial image generation (where "fooling" a classifier is the only goal), in Red Team operations, code must execute correctly while remaining evasive. A GAN generating novel C# transformations would need additional constraints to preserve function and syntax—a challenge that traditional GANs aren’t designed to handle.
Solution in Phase 1: Rule-based logic ensures that every transformed variant remains semantically identical to the original, avoiding execution failures. Block-based segmentation provides controlled modifications that maintain structural integrity.
GANs Lack Awareness of C# Compilation Rules
Neural networks don’t inherently understand C# syntax, dependencies, or compilation constraints. Without strict training constraints, a GAN attempting code transformations might produce outputs that don't compile or cause unintended runtime errors.
Solution in Phase 1: Instead of blindly learning transformations, rule-based logic enforces constraints that guarantee valid outputs. Every change adheres to predefined syntax-safe modifications.
One of the biggest challenges in ML-based GAN training is the need for a large, high-quality dataset.
A GAN that modifies C# payloads would need thousands (or millions) of labeled examples of transformations that evade detection while preserving functionality. By starting with Phase 1, we generate structured, rule-based transformed samples, creating a clean dataset for training a future ML-driven GAN.
Phase 2: Transitioning to Hybrid ML-GAN
While rule-based transformations provide strong obfuscation, they remain constrained by predefined logic. The next phase of Turul GAN development involves evolving toward a hybrid ML-GAN model, integrating:
- Adversarial Learning: ML-based transformations that generate evasive payloads based on real-time interactions with detection models.
- Conditional GANs (cGANs): Guided learning that ensures transformed code remains both evasive and functional.
- Reinforcement Learning (RL): Training the generator to optimize evasion success while maintaining operational integrity.
By combining structured rule-based logic with adaptive ML-driven transformations, Turul GAN will move beyond static obfuscation toward a more intelligent evasion system—one capable of learning and evolving alongside modern EDRs.
Next Blog Posts:
In the next few blog posts, we will introduce, with videos, the current use cases for the technology. These range from powering other C2s to acting in a CICD pipeline of offensive tools, to generating unique variants of loaders.
We will also introduce how behavioral detections are handled currently, and the future situation there.
Our goal is to replace the need for any reverse engineers and human evasions developers long term, and have achieved a working solution that goes *some* of the way there currently in one code language.
If you are interested in more please reach out to us.